1 安装
- 编译器:
g++>4.8或者clang - 依赖:BLAS 库比如
libblas,openblas对于不同的场景,我们会需要依赖不同的库。在这里,我们暂时不使用 GPU,所以不安装 CUDA。
git clone --recursive https://github.com/dmlc/mxnet
1.1 目录结构
|- mxnet |
mxnet 依赖于 dmlc-core,ps-lite 和 mshadow 三个项目。在我看来,mxnet 实际上可以分为两部分。一部分我称之为 mxnet core,另一部分我称之为 mxnet api。在 core 中, include 文件夹中定义了一套 c api 供其他语言比如 python,scala 调用。mxnet core 并没有实现完整的神经网络训练逻辑,它定义了神经网络如何做前向后向传播,但实际训练时的迭代次数, KV Store 的起停等逻辑则是包含在 mxnet api 中的,所以 python,scala 等接口都有一套自己的实现逻辑。
1.2 编译
mxnet 现在有两套编译系统,一套直接基于 make,另一套基于 cmake。推荐使用 make,因为功能更全。现在的 mxnet 的 cmake 脚本不支持编译 scala。
可以通过编辑 make/config.mk 文件来配置编译选项。对于我们而言,我们暂时不使用 GPU。同时我们需要与 Spark 结合,所以需要分布式的 KV Store。 在 make/config.ml 下,修改配置如下:
USE_DISK_KVSTORE = 1 |
因为分布式 KV Store 依赖于 protobuf 和 zmq,我们需要安装对应的依赖库。
开始编译
cd mxnet |
若编译成功,你可以在 lib 目录下找到 libmxnet.so 文件。
2 参数服务器的优势
现在 Spark 基本是大数据处理的事实标准,Spark MLlib 也实现了许多机器学习算法,但 Spark 其实仍是基于 Map/Reduce 计算模型的,而这一模型与机器学习算法的需求 并不十分契合。在机器学习中,一个十分重要的步骤是计算参数的最优解,一般使用梯度下降方法: \[ w = w - \lambda\Delta w \]
在 Spark 中,每次迭代时,我们每个 partition 可以计算梯度,然后在 driver 端更新 weights。那么 driver 端必须等待所有 executor 完成梯度计算。一旦某个 executor 出现网络延时等问题, 整个计算过程将受到影响。而参数服务器的目的既是消除这一影响,单个节点计算的延迟并不会影响整体的计算。使同步执行过程变成异步执行过程。比较 mxnet 和 sparkMLlib 中多层神经网络的训练时间,我们可以看到性能的差距。
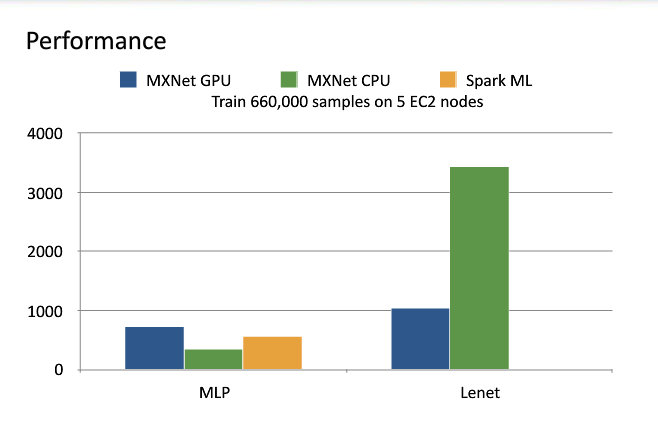
2.1 实现方式
在参数服务器中有三种角色:
- worker: 计算梯度
- server: 从 worker 获取梯度信息,更新参数
- scheduler: 负责调度,worker 和 server 需 scheduler 注册信息
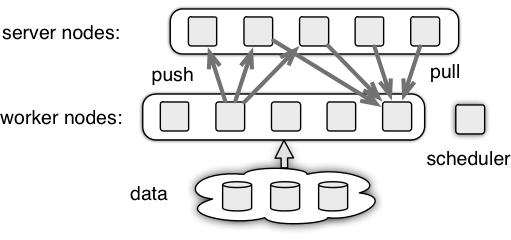
工作流程:
- worker,server 向 scheduler 注册,获得相关信息
- worker 从 server 端 pull 参数 w
- worker 基于参数 w 和数据计算梯度,然后 push 梯度到 server
- server 更新参数 w
- 反复执行 2-4 这一过程
3 计算模型
主要参考 mxnet 的两篇文章:
http://mxnet.readthedocs.io/en/latest/system/program_model.html
http://mxnet.readthedocs.io/en/latest/system/note_memory.html
对于用户而言,mxnet 提够了一套接口来定义神经网络。
val data = Symbol.Variable("data") |
如上一段 Scala 代码便定义了一个多层神经网络。而在实际执行时, Symbol 会调用 toStaticGraph 方法转成 StaticGraph 。
StaticGraph 会计算图中节点的依赖并生成拓扑结构。我们知道训练神经网络有两个步骤,前向传播和后向传播。现在有两种不同的后向传播计算方法,
一种是与前向传播共用一个图,而另一种则是显式生成后向传播图节点。
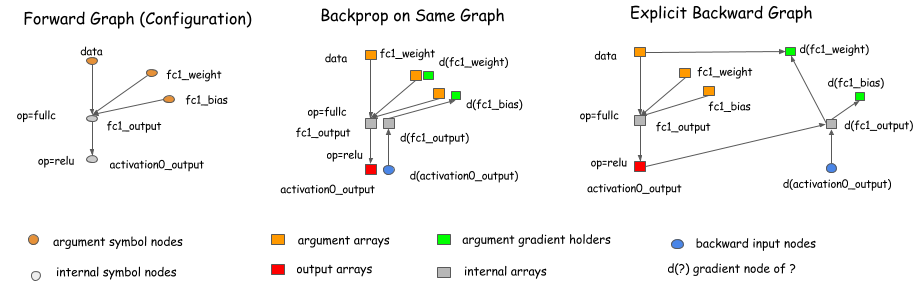
有些深度学习库选择共用一个图,比如 caffe,torch。而另一些则选择显式后向传播节点,比如 Theano。mxnet 同样选择显式后向传播。这样可以为优化提供方便。
4 实例
我们先以一个实例来看看 mxnet 是如何运行的。鉴于 Spark 基本是当前大数据处理的事实标准,我们直接尝试将 mxnet 与 Spark 结合, 从而更接近生产环境的工作流。mxnet 源码中已经有一个与 Spark 结合的实例,我们直接拿来分析。
class ClassificationExample |
为了与 Spark 沟通,毫无疑问首先是初始化 SparkContext 。然后我们需要定义神经网络, getMlp 方法通过 Symbol 定义了一个多层神经网络。然后新建 MXNet 类,定义训练属性。
可以看到,接下来最关键的一步是 mxnet.fit(trainData) 。此方法接受一个 RDD,并获得最终模型。
在 mxnet.fit 方法中,主要有以下几步操作:
- 新建一个 ParameterServer scheduler。这里存在一个问题,一旦 scheduler 挂了,整个参数服务器将不能运作,需要 HA 改进
- 通过 Spark 每个 partition 新建一个 ParameterServer Server
- 对于数据集,每个 partition 新建一个 ParameterServer worker
- 每个 partition 新建一个
FeedForword网络,对应每个 worker,调用FeedForword.fit进行训练。
def fit(data: RDD[LabeledPoint]): MXNetModel = { |
// FeedForword.fit |
可以看到,在 FeedForword.fit 中,基本上是直接调用了 Model.trainMultiDevice 方法。而此方法则实现了神经网络的前向后向传播和 KV store 的更新。
主要步骤:
- 取 batch
- 在此 batch 上做 forward 和 backward 传播
- 从 kv store 更新参数
private[mxnet] def trainMultiDevice(symbol: Symbol, ctx: Array[Context], |
5 组件
5.1 dmlc-core
5.1.1 parameter.h
与 spark 类似,dmlc core 也有一套定义参数的系统。cpp 没有类似 java 的反射机制, 所以在 dmlc 中用到的方法比较 hack:计算类中属性的 offset。
5.1.2 data.h
5.2 ps-lite
postoffice server, worker, scheduler Control: empty, terminate, addnode, barrier, ack van message 新建 KVWorker 和 KVServer 包含 Customer,初始化时新建一个线程用于接收消息
Customer::Customer(int id, const Customer::RecvHandle& recv_handle) |
van 封装通信,现在使用 zmq
5.3 mxnet
Render by hexo-renderer-org with Emacs 24.5.1 (Org mode 8.2.10)